A New Approach to Data Warehousing
Chakra is pioneering a fundamentally different approach to data warehousing by combining two powerful innovations: the performance of DuckDB with bare-metal infrastructure.
Built on DuckDB: The Future of Data Processing
DuckDB represents a fundamental shift in how we process data. While traditional data warehouses rely on distributed systems, DuckDB takes a different approach by focusing on highly efficient single-machine processing. The project has seen explosive growth, surpassing established databases like Postgres in GitHub popularity.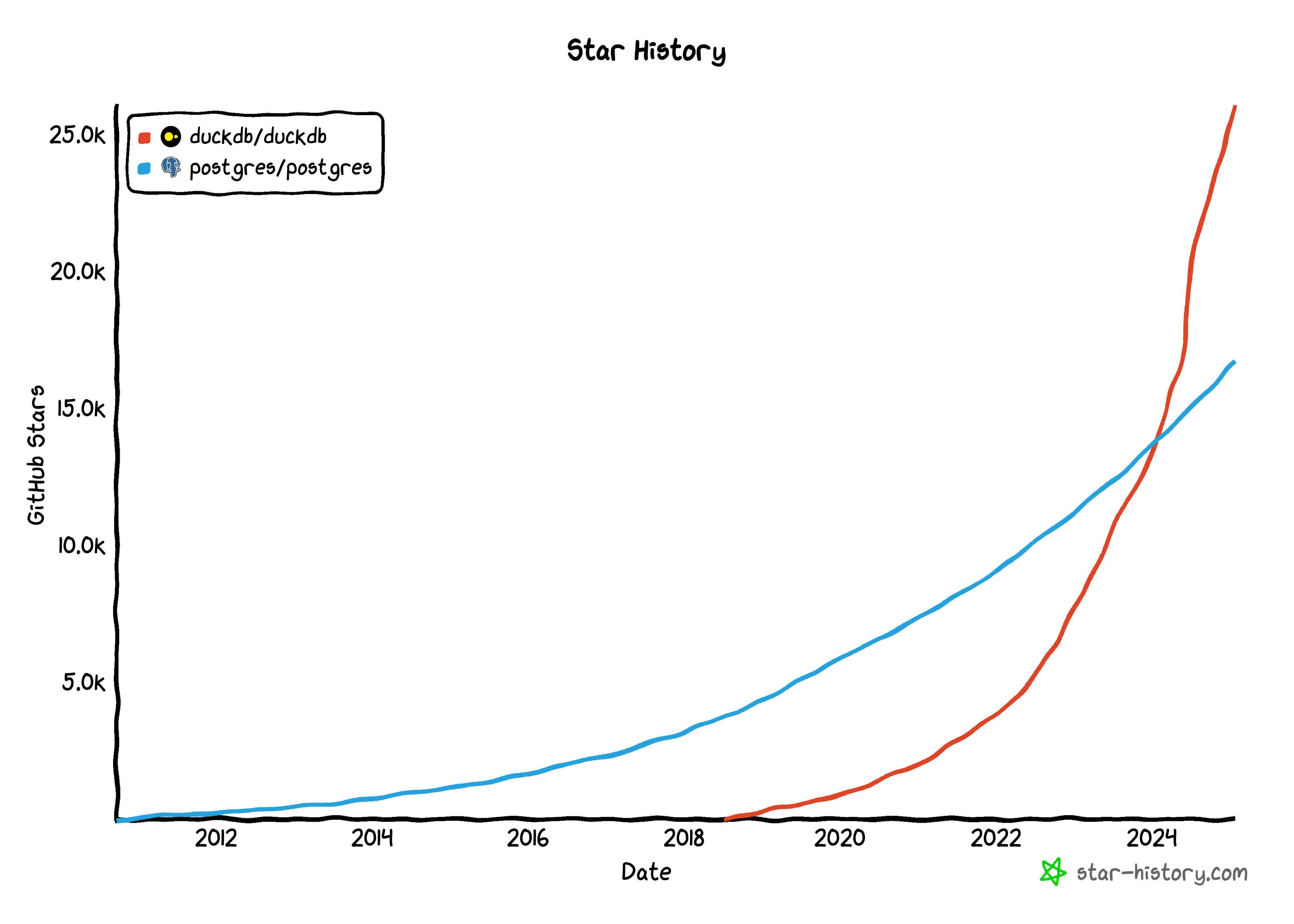
Why DuckDB Is Revolutionary
In-Memory Processing
DuckDB performs computations directly where your data lives, eliminating the “cold-start” problem that plagues distributed systems like Spark. This means no data movement costs and significantly lower latency for most operations.Vectorized Processing
Written in C++, DuckDB’s vectorized processing engine can handle datasets much larger than available memory. Recent benchmarks have shown it outperforming Databricks on many operations by avoiding the overhead of data distribution.Modern Features for Modern Data
DuckDB has rapidly evolved to meet contemporary data needs:- Native support for semi-structured data (JSON, Parquet)
- Direct integration with HuggingFace for AI datasets
- Built-in support for vector similarity search
- Efficient handling of large-scale analytics
SQL-Native Design
Unlike many modern data solutions that require learning new query languages or APIs, DuckDB uses standard SQL. This means:- No retraining needed for analysts
- Familiar tooling and workflows
- Easy integration with existing systems
- Complex transformations without new languages
Choose your own infrastructure
We’ve built using a network of storage and compute providers that allow you to flexibly choose the most cost-efficient and performant option for your needs.Data Ownership
With Chakra, you have full custodial keys to your storage environments without any of the maintenance complexity. We provision object storage for you, but if you ever want access to pull all of your data, you have the keys to do so.